Tyler Cowen points today to a wonky but interesting new paper about publication bias. This is a problem endemic to virtually all scientific research that’s based on statistical analysis. Basically, researchers only publish something if their results are positive and significant. If their results are in the very large “can’t really tell for sure if anything is happening” space, they shove the paper in a file drawer and it never sees the light of day.
Here’s an example. Suppose several teams coincidentally decide to study the effect of carrots on baldness. Most of the teams find no effect and give up. But by chance, one team happens to find an effect. These statistical outliers happen occasionally, after all. So they publish. And since that’s the only study anyone ever sees, suddenly there’s a flurry of interest in using carrots to treat baldness.
The authors of the new paper apply a statistical insight that corrects for this by creating something called a p-curve. Their idea is that if the true effect of something is X, and you do a bunch of studies, then statistical chance means that you’ll get a range of results arrayed along a curve and centering on X. However, if you look at the published literature, you’ll never see the full curve. You’ll see only a subset of the curve that contains the results that were positive and significant.
But this is enough: “Because the shape of p-curve is a function exclusively of sample size and effect size, and sample size is observed, we simply find the free parameter that obtains the best overall fit.” What this means is that because p-curves have a known shape, just looking at the small section of the p-curve that’s visible allows you to 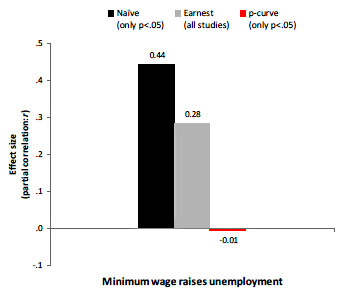 estimate the size of the full curve. And this in turn allows you to estimate the true effect size just as if you had read all the studies, not just the ones that got published.
estimate the size of the full curve. And this in turn allows you to estimate the true effect size just as if you had read all the studies, not just the ones that got published.
So how good is this? “As one may expect,” say the authors, “p-curve is more precise when it is based on studies with more observations and when it is based on more studies.” So if there’s only one study, it doesn’t do you much good. Left unsaid is that this technique also depends on whether nonsignificant results are routinely refused publication. One of the examples they use is the question of whether raising the minimum wage increases unemployment, and they conclude that after you correct for publication bias the literature finds no effect at all (red bar). But as Cowen points out, “I am not sure the minimum wage is the best example here, since a ‘no result’ paper on that question seems to me entirely publishable these days and indeed for some while.” In other words, if a paper that finds no effect is as publishable as one that does, there might be no publication bias to correct.
Still, the whole thing is interesting. The bottom line is that in many cases, it’s fairly safe to assume that nonsignificant results aren’t being published, and that in turn means that you can extrapolate the p-curve to estimate the actual average of all the studies that have been conducted. And when you do, the average effect size almost always goes down. It’s yet another reason to be cautious about accepting statistical results until they’ve been widely replicated. For even more reasons to be skeptical, see here.