What’s the most important takeaway from this week’s kerfuffle over the errors in the Reinhart/Rogoff dataset? Obviously there are public policy implications, since R&R concluded that debt levels above 90 percent of GDP lead to a sharp dropoff in economic growth. This provided important intellectual support during the past few years for the belief that it’s more important to focus on deficit reduction than on unemployment and fiscal stimulus.
In the end, though, although R&R’s results were important, they probably weren’t crucial. As Jared Bernstein notes, deficit hawks were “using research findings the way a drunk uses a lamppost: for support, not for illumination. If the R&R lamppost turns out to be wobbly, the austerions [] will find another one. In this town, I’m sorry to say, you can pretty much go think-tank shopping to buy the result you seek.”
I agree. R&R’s results were convenient to have, but not crucial. People who are dedicated to cutting spending, either for political or ideological reasons, would simply have trotted out other justifications if R&R’s study hadn’t been available.
More important, then, may be the light this shines on the fact that an awful lot of research is based on datasets that are kept private. Megan McArdle pinpoints both the reason for this and the dangers involved:
There are a lot of private data sets out there these days, and a lot of work being produced off of them. Why can’t more of us see it?
Mostly, I suspect, because of the economics of the thing. Assembling a nice private data set is a huge amount of work. You want to be able to mine that work for publishable insights. Very little professional credit accrues to the guy who built a great dataset which everyone else uses to generate elegant new findings. The credit goes to the authors of the elegant new findings. Which means that once you’ve built a dataset, you want to keep the thing to yourself as long as possible.
….Unfortunately, there’s always the possibility that “I want to hold onto it as long as possible so I can publish” can be a cover for “I need to hold onto it as long as possible because if anyone else sees it, it will rapidly become obvious that my results aren’t very robust.” Or, in some cases, for “There are no results because I made the whole thing up.”
This was an issue that was front and center during Climategate. Climate skeptics were unhappy that the raw data collected by various research groups (mostly using public money) wasn’t made available to them, and they made the reasonable point that if your analysis is correct, you shouldn’t be afraid to share the underlying data. Professional researchers, for their part, were reluctant to make their data available because they knew it would generate an enormous flurry of amateur debunkings that they’d have to waste their time picking apart. In 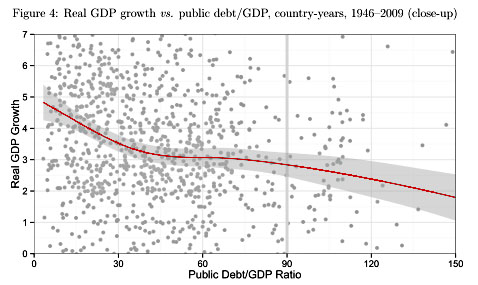 the end, though, releasing the data didn’t make much difference because it turned out the professionals were interpreting it correctly.
the end, though, releasing the data didn’t make much difference because it turned out the professionals were interpreting it correctly.
This is why the R&R incident might be more important for the cause of openness. It’s not just that critics found errors in the dataset once they got hold of it. Even more important might be the fact that once the raw data was available, they were motivated to do certain types of analysis that R&R didn’t do. For example, they discovered that R&R’s results were quite fragile, changing dramatically with the addition or subtraction of just a few observations. They also found that, far from showing a sharp drop in growth when debt passes 90 percent of GDP, the data actually showed a sharp drop between 0-30 percent of GDP and only a rather leisurely decline above 70 percent. Finally, and perhaps most important, UMass economist Arindrajit Dube took a closer look at what the data said about causality, and produced persuasive evidence that R&R’s own data suggested not that high debt leads to low growth, but that low growth leads to high debt. R&R could have performed the same analysis, but for some reason they weren’t interested in it.
As long as the dataset was private, nobody would ever have known any of these things. We could have guessed them—and a lot of people did—but we wouldn’t have had any evidence. Now we do. Unfortunately, as McArdle says, “the incentives are all wrong for data openness.” This episode suggests why it might be worthwhile to try to change those incentives.